{kind=link}

Ever wondered how weather forecasts predict with such accuracy, or how ride-hailing apps estimate travel times so well? Dig deeper, and you’ll find data drives these applications. Essentially, data science applies scientific methods, models, and algorithms to extract valuable insights. To understand these applications, it’s crucial to grasp the core components of data science, which manage the entire data science process.
How the Components of Data Science Drive Real-World Solutions
Now, as we learned from the last part, let’s explore data science with real-life examples. Specifically, we can ask, which of the following is a component of data science? Basically, it’s about getting data, cleaning it up, changing it, looking at it, summing it up, and making pictures of it to find useful info. This info helps companies make good choices, run things better, and make users happy.
For example, apps like OLA and Uber use data science tools, like data acquisition, predictive modeling, and machine learning, to determine travel times, optimize routes, and enhance customer satisfaction. These applications demonstrate how the core components of data science work together to create real-world solutions. Specifically, they gather driver location and availability data, leveraging big data tools to streamline ride-hailing services.
Understanding these components of data science helps businesses transform raw data into actionable strategies. Therefore, it’s an increasingly vital field in today’s data-driven world.
Key Components of Data Science
Data science is built on several essential components, each playing a crucial role in the overall process. Here, we will discuss 5 components of data science which plays the vital role in the data science process.
Data
At the core of data science lies data—the foundation of every analysis, model, and decision-making process. Extracting data from the right sources, such as APIs, websites, and organizations, while ensuring proper permissions, is the first crucial step.
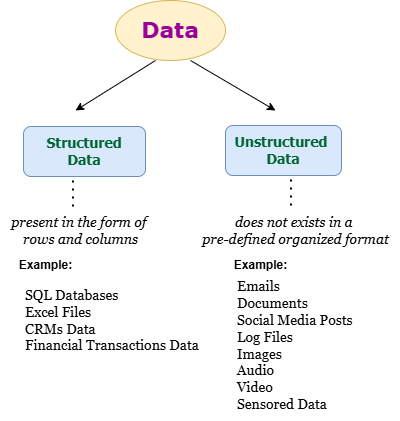
For better understanding, data is categorized into:
Structured Data:
Organized in rows and columns, making it easy to manage and analyze. Examples include databases like MySQL, PostgreSQL, Snowflake, and MS Excel.
Unstructured Data:
Lacks a predefined format, making it more challenging to process. Examples include Big Data tools like MongoDB, Spark, and Hadoop, which handle massive, diverse datasets efficiently.
Programming Languages in Data Science
Coding is very important in data science. Specifically, it helps us make machines learn, build deep learning tools, and do complex data studies. It lets data experts work with big data, make clear pictures, and find useful patterns. Infact, coding is a key component of data science. Some common coding languages used in data science are:
Python:
- Python is one of the most preferred languages in data science due to its simplicity and readability.
- It is dynamically typed, meaning variables can change data types during runtime.
- Also, Python has many built-in sets of tools, like NumPy, Pandas, and Scikit-learn. Because of this, working with data and building models becomes very easy.
R:
- R is widely used in statistical computing and research-based data science applications.
- It has an easy-to-understand syntax, making it accessible for data analysts and statisticians.
- In addition, R offers strong tools for stats and picture making, like ggplot2 and dplyr. Thus, users get complete control over how they look at data and show it.
Statistics in Data Science
Undoubtedly, statistics forms the core support of data science. Specifically, it plays a vital role in examining data, understanding its meaning, and making choices based on that data.
Whether you’re new or experienced, a solid grasp of statistics is essential. Moreover, understanding how machine learning and data science methods work deeply proves invaluable, given their mathematical foundations.
To begin with, the two main areas of statistics used in data science are:
Descriptive Statistics:
Descriptive statistics focus on analyzing, organizing, and summarizing historical data to understand its key characteristics.
- Central Tendency (Mean, Median, Mode): Helps determine how data points cluster around central values.
- Dispersion & Correlation: Measures the spread of data and identifies relationships between different variables.
Inferential Statistics:
Inferential statistics allow us to make predictions and draw conclusions about a larger population based on a smaller sample.
- Hypothesis Testing: Includes Null vs. Alternative Hypothesis, Type I & Type II Errors, p-value, Significance Level, and One-tailed vs. Two-tailed Tests.
- Statistical Tests: Covers Parametric and Non-Parametric Tests used in data analysis.
- Bayesian Statistics: Involves Bayes’ Theorem and Conditional Probability, which are widely applied in machine learning.
Machine Learning in Data Science
In particular, machine learning is a very important component of data science. Essentially, it allows computers to predict trends and find patterns in the processed data. Moreover, it serves as the base for guessing what will happen, which helps businesses make smart choices using models they’ve trained and put into their apps.
Knowing the core components of data science allows you to see how each part is vital to the whole.
Types of Machine Learning:
Supervised Learning:
Supervised learning uses labeled data to predict outcomes. It’s used for regression and classification. Common algorithms include Linear Regression, Logistic Regression, Decision Tree, and Random Forest.
Unsupervised Learning:
Unsupervised learning finds hidden patterns in unlabeled data. It’s used for clustering and reducing data size. Common algorithms are K-Means, DBSCAN, Hierarchical Clustering, XGBoost.
Reinforcement Learning:
In contrast to the methods mentioned earlier, reinforcement learning teaches models to decide by interacting with their surroundings. Specifically, models learn from feedback, like rewards or penalties, making them perfect for robotics, gaming, and AI automation.
Big Data: A Key Component of Data Science
Today, big data is a crucial component of data science and engineering. Essentially, it means huge datasets that need special tools to find useful information. To classify data as ‘big,’ it must meet three key features, known as the 3 Vs of Big Data.
Velocity – The Speed of Data Generation
- Notably, big data is created and handled very quickly, specifically, in real-time or within tiny parts of a second.
- Example: Stock market transactions, IoT sensor data, and AI-powered assistants like Alexa and Siri.
Volume – The Size of Data
- Essentially, big data means huge amounts of info, for instance, from terabytes up to exabytes of storage.
- Example: Social media platforms like Facebook, Twitter, and Instagram generate petabytes of data daily from user interactions.
Variety – The Different forms of Data
- Also, big data comes from many places and is found in different forms. Specifically, it can be organized, partly organized, or not organized at all.
Tools for handling big data:
- Apache Hadoop
- Apache Kafka
- Apache Hive
- Mongo DB
- Microsoft Azure
In summary, we’ve explored the core parts of data science. These five components are the foundation of the entire data science workflow.
Conclusion:
Indeed, data science is a broad field. Essentially, it covers many areas and needs a strong understanding of topics like databases, programming, machine learning, and math. A complete understanding of the various components of data science is vital. With a dedicated learning plan, anyone can master these components within six months and quickly secure data science roles.
FAQs
What are the main components of data science?
Basically, there are 5 primary components of data science:
- Data
- Programming Language
- Statistics
- Machine Learning
- Big Data
What is the purpose of Machine Learning in data science?
Notably, machine learning stands as a key part of data science. Specifically, it builds models that predict or classify. These models help us sort data and uncover hidden patterns.
How is data science different from data engineering?
While both are interconnected, data engineering and data science serve different purposes:
Mainly, data engineering gathers, keeps, and handles huge amounts of data well. Thus, it makes sure the data is organized and easy to use.
Essentially, data science looks at, builds models from, and finds insights in data. Therefore, it solves real-world problems and predicts outcomes.
Do data scientists always work with big data?
While it’s true that big data wasn’t always central, its rising importance has made it a key part of data science. Specifically, big data analytics is now vital for making informed decisions.
Do I need to master programming to become a data scientist?
Actually, you don’t need to be a coding expert! Instead, learn to use tools like Python or R for data work, stats, and machine learning.