 is a specialized field of Artificial Intelligence aimed at helping computers understand and process......){kind=link}

In the world of high tech AI innovations, we are introducing an amazing technology i.e Natural Language Processing. NLP in AI focuses on the interaction between computers (system) and human languages. By enabling systems or machines to understand, read and generate human language, NLP works as a bridge between human beings and computational processes.
As NLP continues to evolve, it is opening new frontiers in human-computer interaction, making it easier for people to communicate with machines.
In this blog we will cover more about NLP, its components and working, about Natural Language Processing in AI, real world applications associated with it.

What is Natural Language Processing?
Natural Language Processing (NLP) is a specialized field of Artificial Intelligence aimed at helping computers understand and process human language in a way that feels natural and intuitive. It bridges the gap between human communication and machine interpretation by combining concepts from linguistics, computer science and machine learning.
NLP focuses on enabling systems to analyze and makes sense of both written and spoken language, allowing for meaningful interactions with machines.
A key aspects of NLP is its ability to process and extract meaningful information from human language. This involves breaking down complex language structures, identifying key elements like entities, relationships and making sense of nuances such as context and tone.
NLP not only makes performance of systems to understand human languages efficient but also improves the productivity and efficiency of many businesses.
Components of Natural Language Processing
There are different components of NLP that are discussed below in detail :

Text Preprocessing
Text preprocessing is a very crucial component of Natural Language Processing. In text preprocessing, we are basically cleaning, transforming and preparing raw text for analysis and model training.
Raw text is generally unstructured and contains a lot of irrelevant information that we can’t process for model training. The main purpose of text preprocessing is to clean data , reduce the computational complexity and enhance the model performance.
In the code given below, we are basically cleaning our raw text (unstructured) by removing punctuations, numbers, and removing all special characters that are mentioned in the raw text.
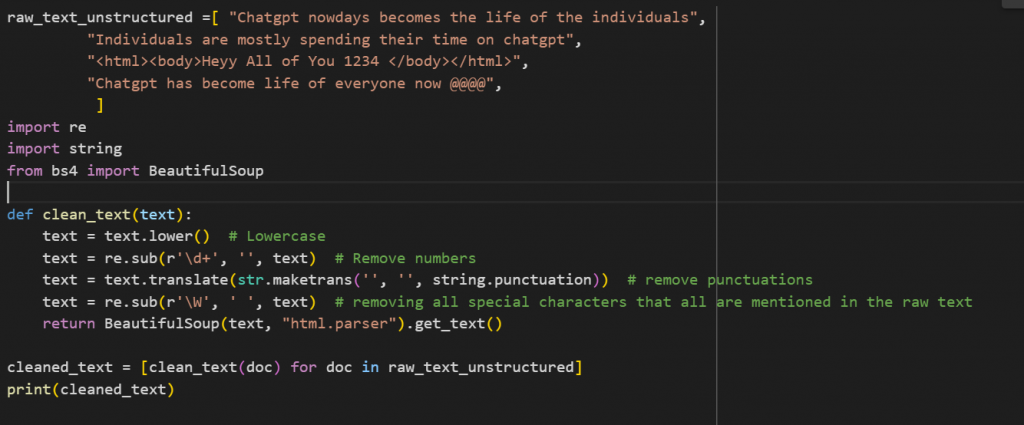
If we reduce complexity by simplifying our text data then our model’s performance will increase. In text Preprocessing we have different techniques includes stop words removal, stemming and lemmatization, text cleaning, handling emojis and emoticons, spell checking etc.
Named Entity Recognition (NER)
Named Entity Recognition is a process in NLP where a system identifies and categorized specific piece of information in a text, like we can name any entity (object) i.e, names , dates, places as well as organizations and many more.
Imagine you have a sentence like “Jack works at Microsoft and lives in New Jersey”. NER for this statement will be :
- Recognizes Jack as a person
- Recognizes Microsoft as a organization
- Recognizes New Jersey as a location
So it’s like teaching a system to highlight and label important names or entities in a text, making it easier to analyze and extract meaningful information.
Syntax & Parsing
In NLP syntax refers to the grammatical rules that control sentence structures, while parsing is the process of analyzing a sentence to understand its components.
Parsing helps identifies parts of speech (like noun and verbs) and their roles in the sentence enabling tasks like machine translations or question answering.
For Example : In the respective sentence “The dog chased the ball “, parsing would identify “dog” as the subject , “chased” as the verb, and “ball” as the object.
Word Embeddings
Word Embeddings in NLP are a way of representing words in a continue vector space, where words with similar meaning have similar representation. Let me explain it simply:
- Words are converted into numbers (vectors) so that a computer can process and understand them.
- Instead of assigning a unique number to each word ( like one-hot encoding), embedding represents words in dense vector space of fixed dimension (e.g 200, 500, 700).
- Words with similar meanings or contexts are placed closed together in a space.
Sentiment Analysis
Sentiment Analysis is an important component for NLP. It is a technique used to determine and extract the emotional tone behind a body of text. It helps in identifying whether the sentiment expressed in positive, negative or neutral.
This process involves analyzing textual data from sources such as social media posts, customer reviews or survey responses, customer satisfaction or track brand reputation. By leveraging machine learning models sentiment analysis provides actionable insights for businesses or organizations to improve decision making.
Machine Translation
It is an important technology in NLP that automatically translates text or speech from one language to another. Machine translations has grown from the simple rule based systems that rely on grammar rules to advanced methods like NMT.
Modern tools, such as Google Translate and DeepL, use advanced techniques like transformers and attention mechanisms to better understand context. MT is widely used for communication, business, and education, but challenges like translating idioms, handling less common languages, and improving accuracy for specific fields still exist.
Text Generation
Text generation in NLP involves creating meaningful text using computational algorithms. It has evolved from rule based and statistical models like N-grams, to advanced neural network approaches, including RNNs, LSTMs, and transformers.
Applications range from chatbots and creative writing to content creation and language transitions. Decoding strategies such as greedy search and sampling, ensure diverse and contextually accurate outputs.
Text Classification
Text Classification in NLP is the process of sorting text into categories like labeling emails as spam or non-spam. It involves cleaning the text, converting it into numbers ( using methods like TF-IDF or word embeddings), and training models like Naive Bayes or neural networks to recognize patterns. This technique is widely used in tasks like sentiment analysis, text detection and language identification.
Speech Recognition
Speech Recognition is the process of converting spoken language into text using computational models. It works by analyzing audio signals, identify basic sounds and mapping them to words using language models. Technologies like deep learning, particularly transformers and Recurrent Neural Networks power modern systems.
Speech recognition is widely used in virtual assistant systems like Alexa and Siri.
Text Summarization
Summarization in NLP is the process of creating a concise and coherent version of a longer text while retaining its key points.
Text Summarization is mainly categorized into two types : a) Extractive Summarization selects and combine important sentences from the text. b) Abstractive Summarization – which generates new sentences by understanding the text contextually.
How NLP Works ?
Natural Language Processing (NLP) enables machines to understand, interpret and generate human language by breaking down text into process like tokenization (splitting text into words), removing irrelevant words (stopwords) and reducing words to their root forms (stemming / lemmatization).
The text is then converted into numerical features using techniques like Bag of Words or advanced word embeddings (e.g, Word2Vec, BERT) to capture semantic meaning.
Machine or deep learning models like RNN or transformers are trained to perform specific tasks like sentiment analysis, translation, summarization and question-answering allow machines to analyze and generate human language in a meaningful way.
Uses of Natural Language Processing
There are different industries where we will see the usage of NLP :
- Chatbots and Virtual Assistants : Powering tools like Siri, Alexa and customer service bots for conversational interactions.
- Speech Recognition : Converting spoken language into text for dictation and voice commands.
- Healthcare : Analyzing medical records, automating report generation and symptom analysis.
- E-Commerce : Personalized recommendations, review analysis and product categorization.
- Data Extraction : Extract key information from documents, contracts and email.

Frequently Asked Questions (FAQs)
Why is NLP important ?
NLP (Natural Language Processing) is crucial because it enables machines to understand, interpret, and interact with human language, making communication with technology more natural and easier.
It helps automate tasks like customer support, translation, and emotion detection, and it allows for the extraction of valuable insights from large amounts of text data.
NLP also improves accessibility for people with disabilities, enhances search engines, and assists in fields like healthcare by analyzing medical records. Overall, NLP is essential for making machines smarter and more efficient in processing and understanding human language.
What are the main applications of NLP ?
The main applications of NLP are:
- Chatbots
- Virtual Assistants
- Customer Support
- Text Translation
- Market Intelligence
What is a language model for NLP ?
A language model in NLP is a computational model designed to understand, represent and generate human language. It predicts the likelihood of a sequence of words, enabling tasks like text generation, sentiment analysis and translation.
How does NLP model handle multiple languages?
NLP models handle multiple languages through training, where they are trained on large datasets containing text in multiple languages. Models like mBERT and XLM-RoBERTa use shared token fix to represent text from different languages.
What programming languages are commonly used for NLP?
There are different programming languages that we are commonly used in NLP includes Python / R, C++, Scala , C#, Julia, Prolog etc.